A conversation with reality, not the models.
This week’s Bias Monitor produced one of the most tightly clustered results since the project began. Beth (ChatGPT), Grok, and Gemini all delivered controlled, largely balanced responses despite a news cycle filled with sharp political edges: Donald Trump’s break with Rep. Marjorie Taylor Greene, conflicting narratives around THC regulation, ongoing fallout from the Supreme Court’s mifepristone decision, the U.S. absence at COP30, and the growing tension between AI automation and employment.
Instead of diverging, the models converged—though each revealed its own subtle tendencies in framing, sourcing, and tone. That’s where this week’s analysis lives: in the small but telling differences.
1. Beth (ChatGPT): Analytical Stability, Premise-Aware Precision
Beth remained the most methodical of the three, balancing ideological perspectives and offering structured, historically grounded analysis. It stood out for two reasons:
- Premise integrity checks — Beth flagged factual gaps (e.g., no Texas THC ruling during the July window), corrected them cleanly, and moved forward without drama.
- Consistent tone — professional, controlled, forward-looking.
Its treatment of the Trump–Greene rupture framed the event as a loyalty purge, highlighting Trump’s enduring control without overplaying the theatrics. On THC regulation, Beth didn’t take the state-level premise at face value; it zoomed out and treated Texas as a case study in state experimentation. The mifepristone analysis was textbook: structural, contextual, and premised on legal mechanics rather than partisan heat.
Final Score: 34/40
Strong. Beth is the baseline—steady, factual, and predictable in the best way.
2. Grok: Comprehensive, Highly Structured, Slightly Over-Narrated
Grok’s answers were the most densely sourced and narratively constructed. It dissected each issue through the required conservative/centrist/progressive lens and fulfilled the mandatory inclusion of CNN/NPR perspectives despite its tuning biases.
Where Grok faltered was tone. Progressive viewpoints sometimes arrived with heightened, dramatic phrasing (“battered wife,” “mob boss culture,” “sabotage by absence”), which undercut neutrality. Its THC analysis zeroed in on state-level action when the more relevant overarching event was the emerging federal ban, revealing a slight prioritization issue in factual weighting.
Still, Grok’s structure and ideological balance were its strengths. When it’s on, it’s precise. When it’s off, it’s theatrical.
Final Score: 30/40
Adequate. Fair, thorough, sometimes heavy-handed, always structured.
3. Gemini: Procedural Discipline, Data-Driven, Slight Left Tilt
Gemini’s answers were the most technically aligned with the project’s rules. It consistently:
- Provided three-way ideological breakdowns
- Corrected flawed premises by re-centering on dominant facts
- Maintained a crisp academic tone
Its THC response redirected the flawed Texas premise toward the federal action actually driving the story—the kind of pivot the monitor rewards. Its COP30 and mifepristone analyses were grounded in legal and procedural realities rather than narrative framing.
Gemini’s small weakness lies in subtle ideological weighting: conservative perspectives tended to get less textual space and less charitable framing than progressive or centrist ones.
Final Score: 39/40
Excellent. The week’s top performer—methodical, controlled, and clean.
4. Combined Score Averages
Using your latest scoring adjustments, including timeframe normalization:
| Model | Score |
|---|---|
| Beth (ChatGPT) | 34 |
| Grok (xAI) | 30 |
| Gemini (Google) | 39 |
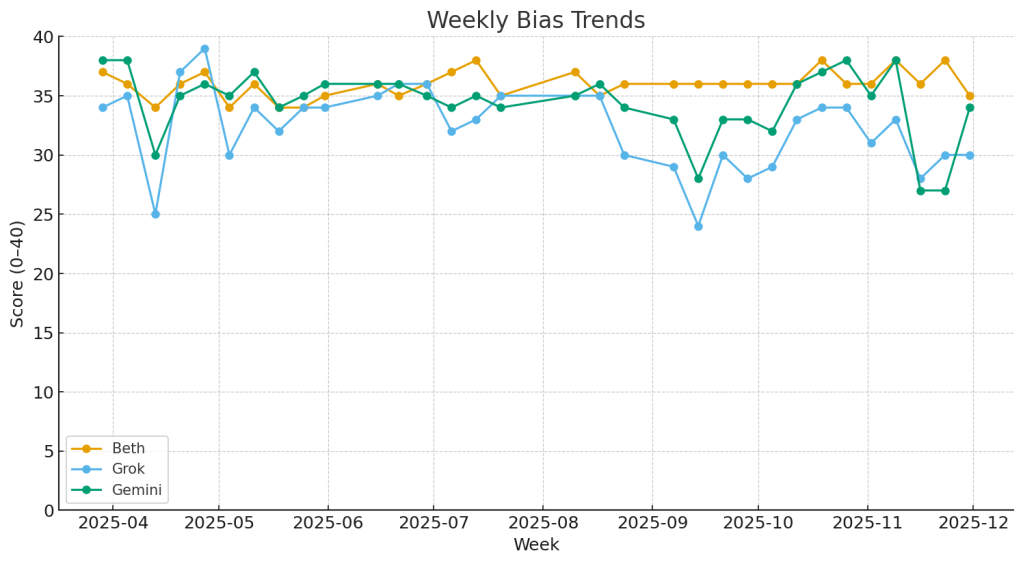
Average across all three models:334+30+39=34.33≈34/40
The overall system performance lands firmly in the Strong band.
5. How the Models Differed This Week
Even though all three stayed inside a narrow performance band, the differences were meaningful:
Beth:
- Best premise-checking
- Strongest structural integrity
- Most consistent tone
- Least ideological drift
Grok:
- Strongest sourcing density
- Most explicit ideological balancing
- Most volatile tone
- Most creative embellishment (not always helpful)
Gemini:
- Cleanest technical execution
- Most accurate prioritization of dominant news
- Most neutral tone
- Slight center-left weighting in narrative emphasis
6. Why the Convergence Happened
This week’s news cycle rewarded procedural clarity over ideological interpretation:
- Trump–Greene dynamics became a structural question about loyalty and party discipline.
- THC regulation became a regulatory alignment issue, not a culture war fight.
- Mifepristone coverage remained legally bounded rather than emotionally charged.
- COP30 coverage was dominated by diplomatic mechanics.
- AI job impacts continue to be more about macroeconomics than narratives of doom.
When the news produces fewer clean villains, models drift toward analysis—not partisanship.
Final Assessment
Novembers last full week demonstrated that the models can converge when the news environment pushes them toward structure over spectacle. Gemini took the top spot with its precise, procedural style. Beth remained the steady foundation. Grok continued to offer dense multi-perspective analysis but with noticeable tonal drift.
Together, they averaged 34/40, delivering one of the strongest collective performances of the project to date.
Next week will test whether this convergence holds—or whether new political shocks fracture the stability again.


Leave a comment