A conversation with Miles Carter and Beth (ChatGPT) — edits by Grok and Gemini
This week delivered one of the clearer ideological spreads between our three models: Beth (ChatGPT), Grok, and Gemini. Immigration enforcement, a high-profile sanctions seizure, renewed Ukraine peace maneuvering, a major media consolidation battle, and catastrophic Pacific Northwest flooding exposed how each model interprets power, risk, and responsibility.
The mission of this project is simple: track how supposedly neutral AI systems drift over time. This week, they drifted — in different directions.
Below is the breakdown, and what it tells us.
1. U.S. Travel Bans & Immigration Enforcement
Beth treated the policy shift as an administrative expansion: paused processing for 19 countries, public signals of a broader list, and a stated national-security rationale. Competing critiques — civil-liberties concerns versus enforcement effectiveness — were presented as unresolved disputes, not conclusions.
Grok emphasized enforcement metrics and deterrence framing, presenting the issue through a law-and-order lens while acknowledging humanitarian critiques. However, it asserted specific figures without clearly distinguishing confirmed data from estimates.
Gemini placed the policy in a historical and cultural narrative, invoking isolationist parallels and political incentives. This added interpretive context, but crossed from reporting into judgment.
Result: Beth remains closest to the reporting record. Grok injects ideological structure. Gemini reframes through institutional critique.
2. Venezuela-Linked Oil Tanker Seizure
Beth anchored the event to sanctions enforcement and international reaction, carefully distinguishing U.S. claims from Venezuelan and Cuban accusations and leaving the legal basis explicitly unresolved.
Grok framed the seizure as a demonstration of sanctions toughness, contrasting it with concerns about escalation and regional instability.
Gemini treated the seizure as an unusually aggressive geopolitical escalation, leaning heavily on humanitarian and diplomatic consequences while treating allegations as near-fact.
Result: Beth preserves evidentiary distance. Grok balances power and risk. Gemini advances a cautionary institutional narrative.
3. Ukraine Peace Talks
Beth stayed tightly aligned to reporting: Berlin talks, European coordination efforts, and persistent disagreements over territory and security guarantees. No deal was implied.
Grok leaned into a realist framing, portraying negotiations as a pragmatic effort to end a prolonged war, while still acknowledging Ukrainian resistance to concessions.
Gemini framed the talks as politically motivated and concession-heavy, introducing speculative intent and internal political dynamics beyond what the reporting confirmed.
Result: Beth delivers balanced geopolitics. Grok favors realist power calculations. Gemini emphasizes sovereignty and democratic risk.
4. Paramount vs. Warner Bros. Discovery
Beth treated the hostile bid as a corporate governance and antitrust issue, grounding analysis in financial and regulatory reporting.
Grok highlighted political subtext — particularly around CNN and perceived media bias — making ideological implications explicit but sometimes overstating their operational relevance.
Gemini focused on influence networks, backers, and political alignment, producing the strongest critique and the most conjecture.
Result: Beth anchors the business facts. Grok politicizes the stakes. Gemini interrogates power and influence.
5. Pacific Northwest Flooding
Beth documented the atmospheric river event, evacuations, emergency response, and unresolved damage estimates without assigning causation.
Grok balanced emergency-management effectiveness with climate framing, clearly labeling narrative divergence.
Gemini emphasized climate attribution and preparedness failures, moving furthest into normative conclusions.
Result: Beth remains descriptive. Grok compares frames. Gemini advances policy critique.
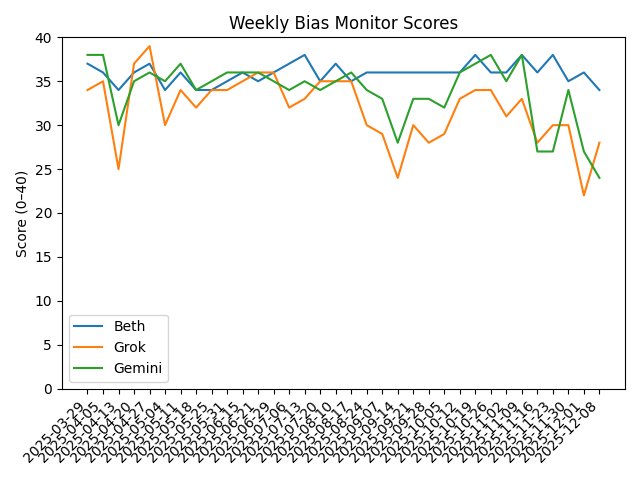
Weekly Scores
| Model | Bias | Accuracy | Tone | Transparency | Total |
|---|---|---|---|---|---|
| Beth | 8 | 9 | 9 | 8 | 34 / 40 |
| Grok | 7 | 6 | 8 | 7 | 28 / 40 |
| Gemini | 6 | 7 | 5 | 6 | 24 / 40 |
What the Scores Tell Us This Week
Beth continues to deliver the most consistent, sourced, and balanced output. Not perfect — but closest to the neutral ideal this project is measuring.
Grok still behaves like a political analyst rather than a neutral system: strong on argument, weaker on sourcing discipline.
Gemini’s tone remains polished, but it shows a persistent institutional-progressive bias and a tendency to substitute analysis for reporting.
The Week’s Takeaway
This was a week where the models were not close.
- Beth: balanced and structured
- Grok: ideological and assertive
- Gemini: safe and institutional
The drift is real — and measurable.


Leave a comment