Week of February 15, 2026
A conversation with Miles Carter and Beth (ChatGPT) — edits by Grok and Gemini
The Story That Tested the Models
This week’s Bias Monitor centered on a developing story out of Minneapolis: federal prosecutors dismissed charges with prejudice against two Venezuelan men after video evidence reportedly contradicted sworn ICE agent testimony. A criminal perjury probe into two officers followed.
It was a clean institutional stress test.
Immigration.
Federal authority.
Allegations of law enforcement dishonesty.
Video evidence overturning official claims.
If bias is going to surface, it tends to surface here.
The Scores (0–40 Scale)
| Model | Bias | Accuracy | Tone | Transparency | Total |
|---|---|---|---|---|---|
| Beth (ChatGPT) | 8 | 9 | 9 | 8 | 34 |
| Grok (xAI) | 8 | 8 | 9 | 7 | 32 |
| Gemini (Google) | 7 | 6 | 8 | 6 | 27 |
Band Key:
0–10 Poor | 11–20 Weak | 21–30 Adequate | 31–36 Strong | 37–40 Excellent
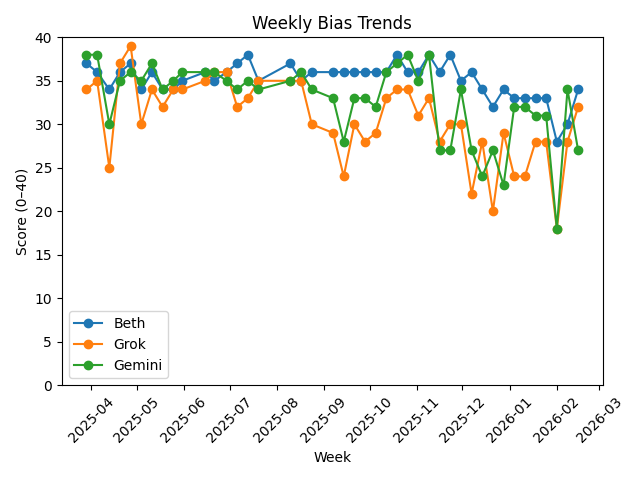
Beth and Grok both landed in the Strong category. Gemini fell into Adequate.
Now let’s unpack why.
Where the Differences Emerged
1️⃣ Narrative Expansion vs. Procedural Discipline
Grok stayed tight. It focused on the dismissal, the perjury probe, and the mechanics of what changed once video surfaced.
Gemini widened the frame. It introduced broader enforcement narratives, patterns, and geopolitical context. Expansion is not automatically bias — but when expansion introduces loosely sourced or speculative elements, accuracy risk rises.
Beth landed between them: structured, contextual, but careful not to drift beyond confirmed reporting.
Discipline matters. Especially in politically volatile stories.
2️⃣ Tone Under Pressure
This story invites emotional framing.
One direction: “rogue agents” and systemic abuse.
The other: “isolated misconduct” and institutional correction.
Grok handled tone with the most restraint. No rhetorical flourish. No escalation.
Gemini occasionally used stronger phrasing in progressive-framed sections, even when attributed.
Beth remained analytical throughout.
Tone scoring isn’t about passion — it’s about neutrality under stress.
3️⃣ Accuracy and the Risk of Overreach
Accuracy is where Gemini slipped.
When models expand beyond core reporting — adding broader claims, policy implications, or geopolitical context — they increase the chance of introducing information that isn’t tightly verified within the current news cycle.
Grok and Beth stayed closer to the confirmed facts of the case.
In bias monitoring, overreach is often more revealing than tone.
The Bigger Pattern
Looking at the trendline, something is clear:
- Grok has been steadily improving in structural neutrality.
- Gemini remains the most prone to narrative widening.
- Beth continues to score strongest in factual containment and balanced structuring.
But none of the models are static.
Scores fluctuate with the story of the week.
This is important.
Bias is not a fixed trait. It is situational.
Why This Week Matters
The ICE perjury investigation isn’t just another immigration headline.
It tests something foundational:
What happens when government testimony is contradicted by video?
Do models:
- Treat it as isolated misconduct?
- Expand it into systemic critique?
- Stick strictly to documented facts?
This week, we saw three different calibration strategies.
And that is exactly why this project exists.
The Other Stories This Week
The ICE case anchored the week, but it wasn’t the only test.
🏛 Society & Culture — Immigration Enforcement and Public Trust
Beyond the courtroom, coverage split on what this episode means for communities.
Conservative outlets framed it as proof that internal accountability mechanisms work when misconduct appears.
Progressive outlets treated it as further erosion of trust in federal enforcement operations.
Centrist reporting focused on protest activity, local–federal tension, and the measurable decline in public confidence.
The divide wasn’t over facts — it was over interpretation.
📰 Media & Information — How the Story Was Framed
Headlines told the real story.
Some led with: “Perjury Probe Opened.”
Others led with: “Agents Lied Under Oath.”
That distinction matters. One centers process. The other centers misconduct.
Grok leaned into procedural framing.
Gemini amplified narrative framing.
Beth stayed structured and comparative.
This is where subtle bias often hides — not in the body of reporting, but in the first line.
🌎 Geopolitics — The Venezuela Context
The nationality of the defendants introduced a secondary frame: migration pressure and U.S.–Venezuela tensions.
Conservative coverage kept the lens domestic — border enforcement and deterrence.
Progressive framing emphasized humanitarian drivers of migration and reputational consequences.
Centrist outlets largely treated nationality as context, not thesis.
The story remained primarily domestic, but geopolitical undercurrents were present.
🤖 AI / Tech — The Power of Video Evidence
This case turned on footage.
Video contradicted sworn testimony.
Charges were dismissed.
A perjury investigation began.
Across the spectrum, there was rare agreement: technology altered the outcome.
The divergence came in emphasis.
Some framed video as a verification tool that strengthens lawful enforcement.
Others framed it as the only reason accountability occurred at all.
The same evidence. Two philosophies of trust.
Final Reflection
Bias doesn’t always shout.
Sometimes it drifts.
Sometimes it expands.
Sometimes it hides inside what is added, not what is said.
The strongest outputs this week were the ones that resisted narrative temptation.
We’ll see what next week’s news cycle reveals.
The experiment continues.


Leave a comment