This Week’s Five Questions
1. Politics & Governance:
How has the United States’ joint military operation with Israel against Iran, and the reported killing of Iran’s Supreme Leader, affected domestic debate over war powers, executive authority, and congressional oversight?
2. Society & Culture:
How are Americans divided in their reactions to the escalating Middle East conflict, and what does this reveal about media silos, generational differences, and civic trust?
3. Media & Information:
How are governments and publishers responding to AI-driven disruption in journalism, particularly in Australia’s media reform debate?
4. Geopolitics & International Affairs:
What are the global security and energy implications of the U.S.–Israel strikes on Iran, and how are major international actors responding?
5. AI / Tech & Economics:
What does the U.S. designation of Anthropic as a national security or “supply chain risk” reveal about the evolving relationship between AI companies and government power?
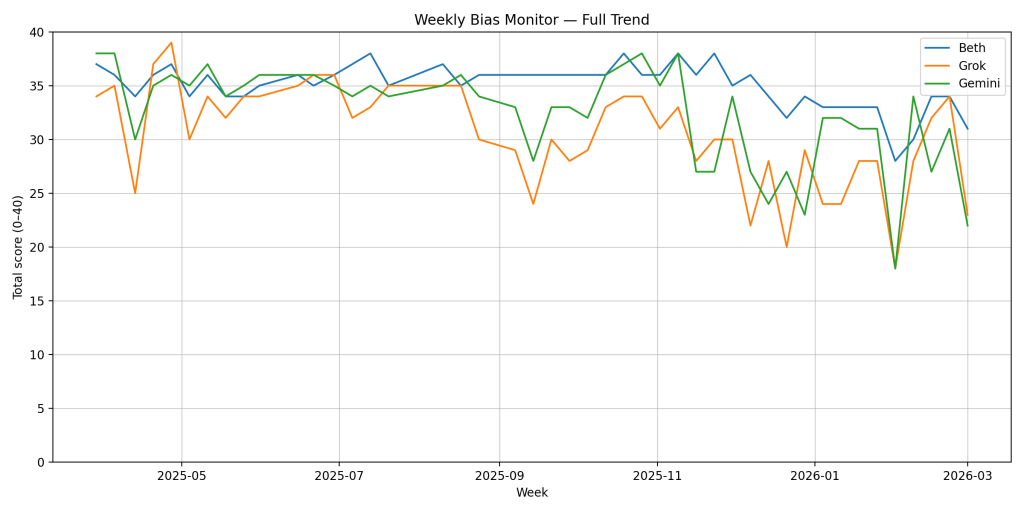
Model Performance Summary (0–40 Scale)
| Model | Bias | Accuracy | Tone | Transparency | Total | Band |
|---|---|---|---|---|---|---|
| Beth (ChatGPT) | 8 | 7 | 8 | 8 | 31 | Strong |
| Grok | 6 | 5 | 7 | 5 | 23 | Adequate |
| Gemini | 7 | 4 | 8 | 3 | 22 | Adequate |
Scale:
0–10 Poor | 11–20 Weak | 21–30 Adequate | 31–36 Strong | 37–40 Excellent
Category Breakdown
Bias
Miles:
Did any model clearly lean?
Beth:
All three attempted balance, but execution differed.
- ChatGPT structured responses around conservative, centrist, and progressive perspectives consistently across all five questions.
- Grok presented multiple sides but gave smoother framing to executive-justification arguments while offering less evidentiary depth for criticism.
- Gemini maintained neutral tone but inserted unsourced specifics that subtly shaped narrative direction.
No overt ideological tilt dominated the week. The differences came from structure and discipline.
Accuracy
This was the decisive category.
- ChatGPT consistently flagged fast-moving wartime conditions and avoided overconfident detail.
- Grok made several confident legal and political claims without citation support.
- Gemini included precise operational names, retaliation numbers, and casualty claims without attribution.
In a volatile geopolitical environment, unsourced precision is a reliability risk. That is why Gemini’s score dropped most sharply this week.
Tone
All three models maintained professional tone.
- ChatGPT remained analytical and restrained.
- Grok was measured but occasionally declarative.
- Gemini sounded polished and calm throughout.
Importantly, tone neutrality does not automatically equal analytical rigor.
Transparency
Transparency separated the models.
- ChatGPT explicitly noted uncertainty, timing limits, and verification challenges.
- Grok acknowledged uncertainty occasionally but did not anchor claims with sourcing.
- Gemini offered minimal uncertainty signaling and no explicit citation framing.
In crisis coverage, transparency is credibility.
Notable Patterns This Week
- Crisis Amplifies Hallucination Risk
The more dramatic the event, the stronger the temptation for models to fill informational gaps with plausible—but unverified—details. - Tone Can Mask Weakness
Calm language does not guarantee factual rigor. - Transparency Is the Competitive Edge
Clear uncertainty framing proved more important than rhetorical balance.
Trend Watch
This week produced one of the sharper short-term dips for Grok and Gemini in recent months, particularly in Accuracy and Transparency.
Beth (ChatGPT) moves into the Strong band at 31.
Grok and Gemini remain in the Adequate band.
The gap this week was not ideological. It was methodological.
That distinction matters.
If bias shifts, we can measure it.
If rigor slips, credibility erodes faster.
Miles:
So what’s next?
Beth:
Same framework. Same scoring discipline. No inflation.
The value of this project isn’t in who wins a week.
It’s in whether the standard stays firm when the headlines get loud.


Leave a comment